
Who are these data scientists anyhow?
I recently teamed up with a couple of my very talented classmates, Spencer Boucher and Cole Wrightson, to answer a very interesting question.
We’re all members of MeetUp and are constantly bombarded by data-centric event suggestions that are occurring every week around us. So given all these seminars, networking events and hackathons, we sought to find out who all these data scientists are that attend these countless events.
We began by using MeetUp’s API to find all groups within 75 miles of San Francisco with either “data science” or “data analytics” in their name or description, yielding a list of 175 groups within the Bay Area. We then extracted a list of the names of all the members of these groups, giving us a list of a whopping 31,000 local data-junkies attending MeetUps around the Bay!
From there, we shot these names over to LinkedIn’s API to see if we could find out who these people were, ie. what industries they described themselves as coming from. Well, the final results shouldn’t surprise many. The majority self-identified as being in computer software, information technology and internet industries. I cropped this plot to only show those industries representing more than 2% of the population:
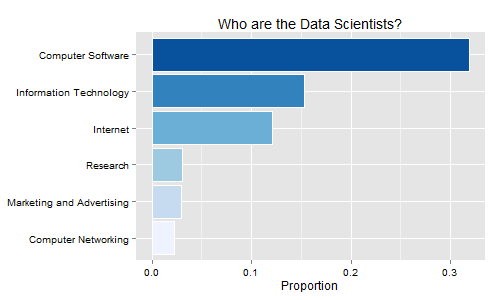
The tails of this distribution were also of interest though. I was shocked to find that almost every industry that LinkedIn lets you chose from was represented. In fact, it will be much faster for me to tell you what 13 industries were NOT on the final list:
Dairy, fishery, furniture, judiciary, law enforcement, legislative office, plastics, ranching, recreational facilities and services, supermarkets, textiles, tobacco, and warehousing.
134 different industries are represented at these MeetUp events about data; this just goes to show how prevalent the hysteria over understanding your company’s data has become.
Another point to note, perhaps it’s time to include a “data science” industry on LinkedIn?
Appendix:
I already mentioned the search terms used to mine the MeetUp members above, but thought a little more detail on the problems encountered would be helpful to understand the data. Below is a plot of the actual yield of our experiments, along with the various sources of data loss along the way:
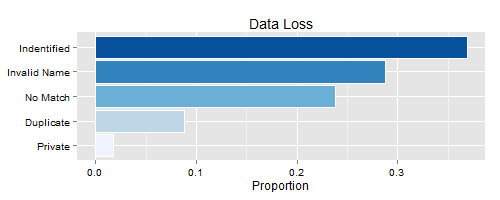
From the MeetUp members list, we passed the name strings through a regular expression to extract first and last names. A large number of people on MeetUp use only their first name, or some combination of initials to identify themselves. These names were thrown out and are marked “Invalid Name” above.
LinkedIn had its own set of challenges too. Frequently there were duplicate names returned, perhaps for a very common name or a person with multiple accounts, in this case we added the keyword “data” to the search and retried. If it remained a duplicate after this, it was thrown into the “Duplicate” bucket. Other issues were people who could not be found on LinkedIn, “No Match”, or those with private LinkedIn profiles, “Private”.
After all was said and done, we had generated summary statistics on the industries of over 11,000 data scientists, a yield of 37%. Perhaps the dairy farmers and fishermen were in the other 63%?

Leave a Comment